



新闻热线 0891-6325020
11月19日下午,由中国工程院院士、西藏大学教授尼玛扎西团队和北京智谱华章科技股份有限公司联合研发的国内首个面向藏语场景的千亿级参数藏语基座大模型“阳光清言”V1.0成果在拉萨发布。

图为“阳光清言”藏语大模型成果发布会现场。记者 欧珠次仁 摄
据研发团队介绍,模型训练使用了约288亿Token的高质量藏语数据,体量和质量均处于当前国内大模型研究领域藏语语料建设的“第一梯队”。

图为中国工程院院士、西藏大学教授尼玛扎西在介绍“阳光清言”藏语大模型研发成果。记者 欧珠次仁 摄
在丰富的“知识底座”的加持下,“阳光清言”在藏语智能回答、文本生成、机器翻译等领域有着优异的表现。
研发团队表示,得益于千亿级参数规模与高质量语料,藏语AI不再只是“大模型世界里的一角”,而是拥有了真正匹配国际主流水平的“超级数字大脑”。
图为“阳光清言”藏语大模型界面。
值得关注的是,“阳光清言”并非单一垂直应用模型,而是面向多行业、多场景的基座大模型。基于这一底座,可面向西藏重点领域衍生出文旅服务、文化传承、藏医药发展与高原健康等一系列行业大模型,为西藏各类行业提供统一的藏语智能底座。
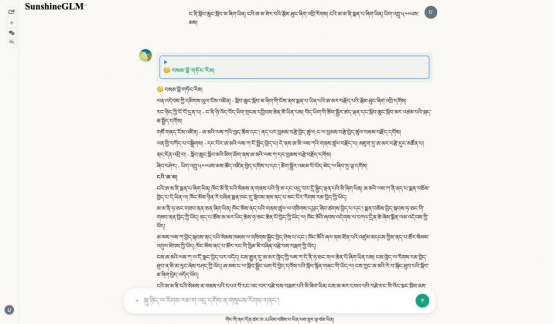
图为“阳光清言”藏语大模型文本生成截图。
“阳光清言”藏语大模型的研发,是补齐藏语在智能化发展中长期存在“数据少、算力弱、人才缺”这一短板的重要一步,使得藏语言有机会在新一轮人工智能竞争中,抢占藏语智能领域国际技术话语权。
关于我们 丨联系我们 丨集团招聘丨 法律声明 丨 隐私保护丨 服务协议丨 广告服务
中国西藏新闻网版权所有,未经协议授权,禁止建立镜像
制作单位:中国西藏新闻网丨地址:西藏自治区拉萨市朵森格路36号丨邮政编码:850000
备案号:藏ICP备09000733号丨公安备案:54010202000003号 丨广电节目制作许可证:(藏)字第00002号丨 新闻许可证54120170001号丨网络视听许可证2610590号




